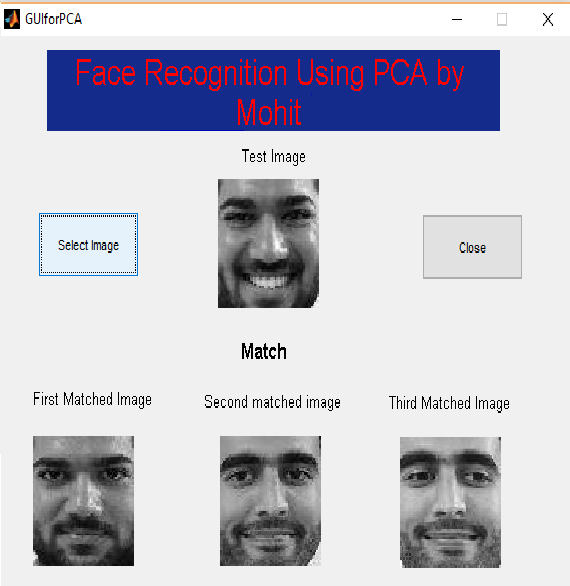
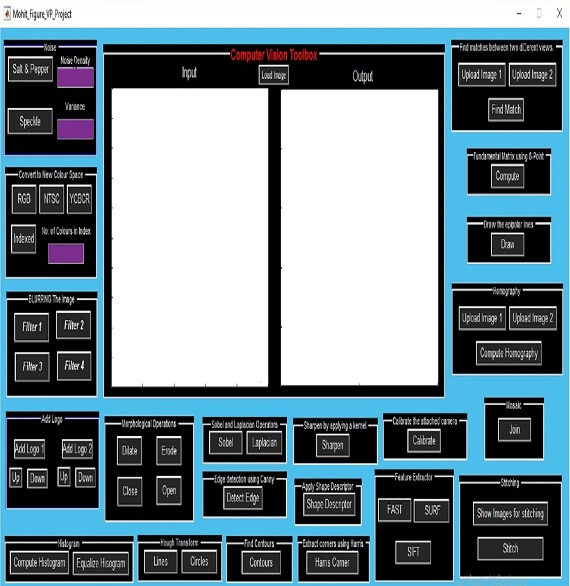
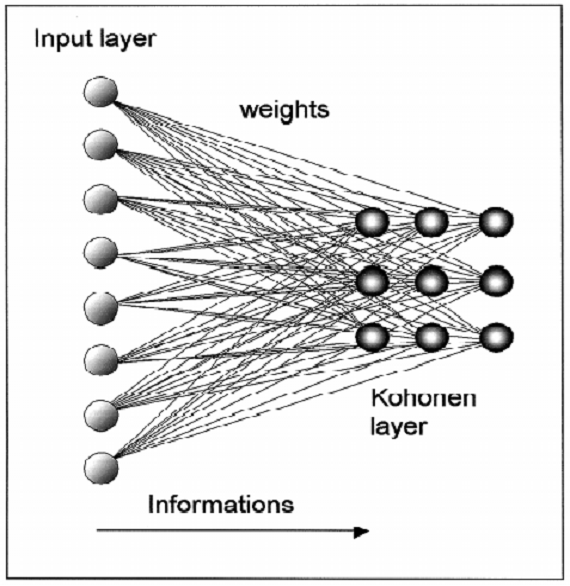
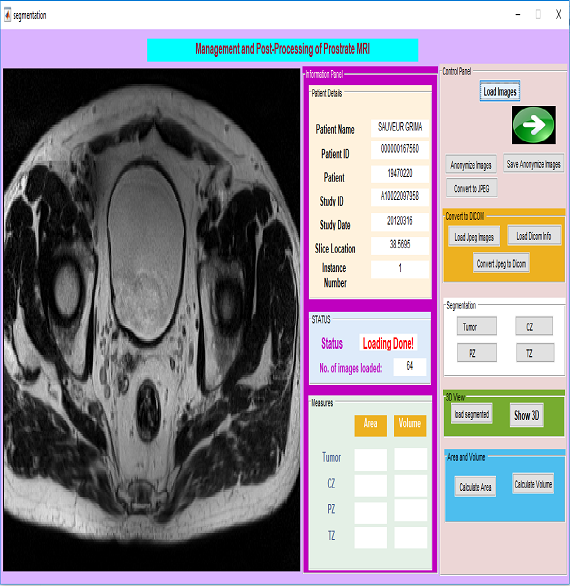
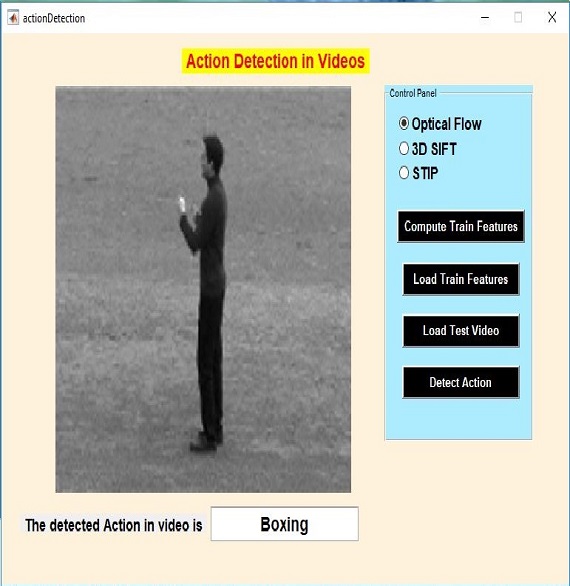
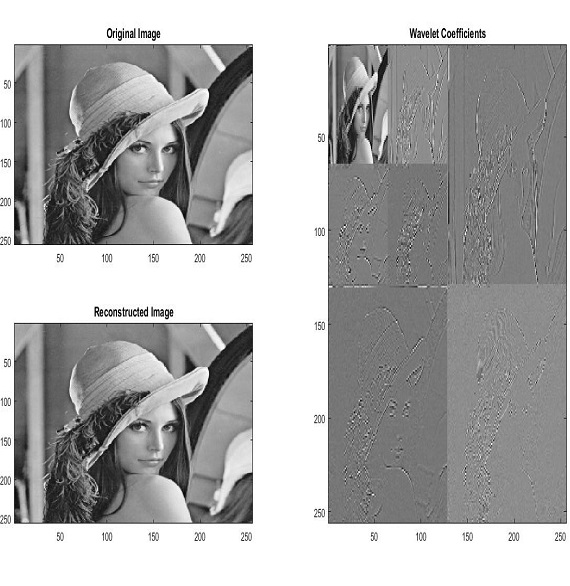
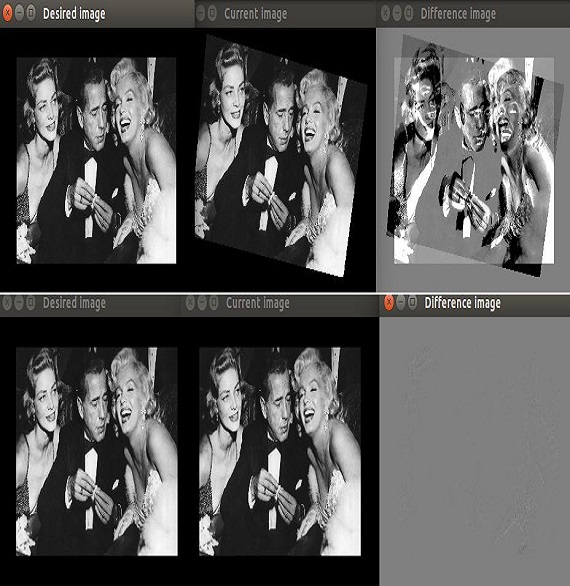
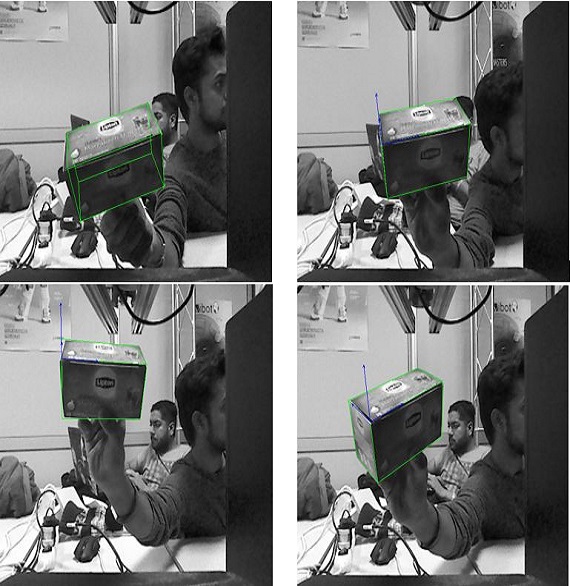
About Me
I am Mohit Ahuja and I love to build and work on robots. I am fully passionate and dedicated towards exploring
various challenges in the field of Robotics, Computer Vision and Deep Learning. I am keen to collaborate and
work with robotics researchers across the globe so that I can help solving interesting problems and at the
same time, can develop deeper understanding of various innovative technologies linked with robotics. Some
of my research interests, but not limited to, are Control & Perception for mobile robots, Deep learning for
visual recognition and SLAM & Probabilistic robotics.
Contact Details
Mohit Kumar Ahuja
Martin Linges vei 25
1364 Fornebu,
Oslo, Norway.
+47-94162049
MohitKumarAhuja@gmail.com